Python multiprocessing in 5 minutes
I was missing an easy-to-read example of the basic use of Python Multiprocessing so I decided to write one.
Conceptual review: we want multiprocessing because we have access to machines with multiple CPU cores (either virtual or physical) and without multiprocessing all potentially parallelizable work will run sequentially. Assuming we have N real cores, we would be able to divide the execution time by N. If we have N virtual CPUs each of which mapped to a physical core with SMT, the factor would be (N/2 + delta), where delta is a number considerably lower than N/2, probably between 0.1 * N/2 and 0.2 * N/2. Whatever the case is, there is a very large potential reduction of execution time for parallelizable workloads. For an 8 vcCPU virtual machine, dividing execution time by 4.4 would be a reasonable estimation of how multiprocessing is helpful. Finally, we want multiprocessing rather than threads because Python threads are not efficient due to the GIL.
This example covers the following situations:
- execution of several different functions in parallel each of which receiving different arguments
- execution of several instances of the same function in parallel each of which receiving different arguments
Here is some (hopefully) self-explanatory code:
def main():
print('Starting the main program')
# DO WHATEVER STUFF NEEDS TO BE DONE HERE
print('Starting background multiprocess work\n')
# this is the list of functions that we want to execute in parallel
# the list can be made of different functions or the same function
# in every position, depending on the real world case
worker_functions = [ worker_function, worker_function,
worker_function, worker_function,
worker_function ]
# this is a list with the arguments that will be passed to each independent function invocation
# in a real world case it would probably include data chunks to be processed or paths
# to CSV files or ...
worker_args = [ ('Worker1', 'New York'), ('Worker2', 'London'),
('Worker3', 'Sydney'), ('Worker4', 'Lisbon'),
('Worker5', 'Paris'), ]
procs = []
worker_ids = {}
# instantiating the process with its arguments
for function, arg_list in zip(worker_functions, worker_args):
proc = Process(target=function, args=arg_list)
proc.daemon = True
procs.append(proc)
proc.start()
pid = proc.pid
# store the relationship between the process ID and the worker id
# we are using the second argument to identify the worker
worker_ids[pid] = arg_list[1]
# wait for completion - the join call only returns immediatly if the process is done
# and waits for completion if the process is still running
# since we call it for all of them we are in the loop until all of them are done
for proc in procs:
proc.join()
The code above goes as far as to launch the 5 processes in background and wait for them to complete. But what happens next? Ideally, we would like to be aware of the exit code of every process before we go forward with the execution of the main program:
print('\nNow we will check the process exit codes of our processes:\n')
# get the exit codes
status_OK = True
for proc in procs:
pid = proc.pid
exit_code = proc.exitcode
if exit_code != 0:
status_OK = False
# review each processe's exit code
print(f"{worker_ids[pid]:10} returned: {exit_code}")
# check if all processes returned 0
if status_OK is not True:
# in a real world situation we would want to react to this with more than a simple message
print('\nWARNING: At least one process exited with an error')
# now we can go on with the main program execution and collect results from the parallel execution
print('')
print('Now, business as usual. The program continues...')
Obviously, for this to work we need a worker_function. Here is a fictional function that can be used with the code structure above:
def worker_function(p1, p2):
# we will pretend we are doing heavy work that takes time by sleeping :-)
interval = random.randrange(DELAY + 1)
print(f"Begin: {p2:10} | estimated work time: {interval:2}")
time.sleep(interval)
print(f"End : {p2:10} | estimated work time: {interval:2}")
# we will pretend that things could go wrong by randomly exiting with either 0 or 1
status = random.randrange(2)
# note that we use exit and not return because we must deliver the exit code to the parent process
exit(status)
Does it work, though? If you'd like to see this example in action you can simply execute:
git clone https://github.com/ghomem/python-blueprints.git
python3 python-blueprints/multiprocessing/multiproc-blueprint.py
The result should be something like this:
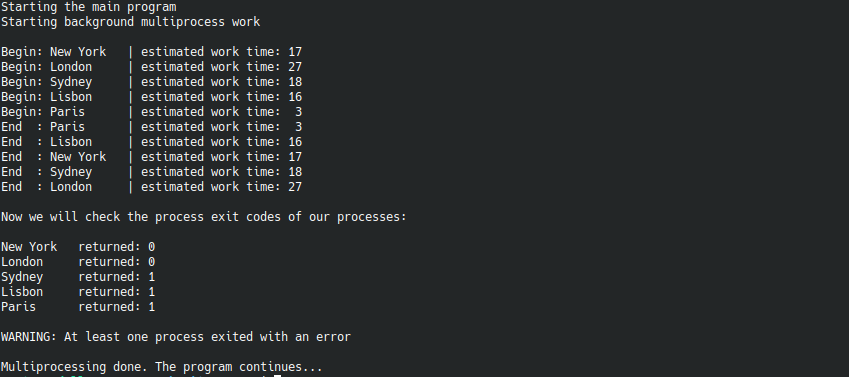
That's it. Hopefully, this 5 minute read saves more than 5 minutes to whoever reads it.